强化学习求解方法非常多,本部分仅仅从宏观上,讲述求解强化学习的算法类型,具体求解细节,后续再分小节进行介绍。
强化学习是找到最优策略 使得累积回报的期望最大:
其中, 状态到动作的映射;
表示从状态
到最终状态的一个序列
; 累积回报为
,
为第
个状态执行动作,产生的回报。
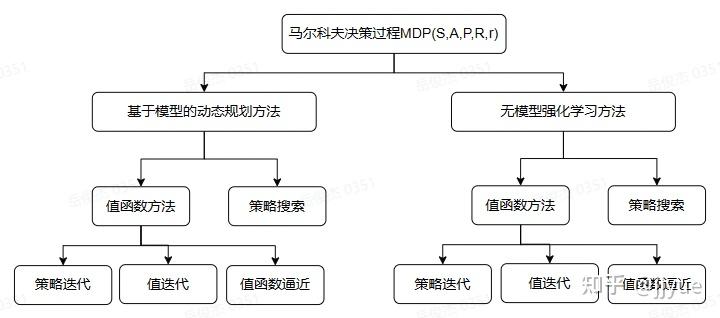
从广义上讲,强化学习是序贯决策问题。第2节,我们已经介绍了强化学习可以建模成马尔可夫决策过程MDP框架。马尔科夫决策过程可以利用元组 来描述,根据转移概率
是否已知,可以分为基于模型的动态规划方法和基于无模型的强化学习方法。
3.2.1和3.2.2主要介绍值函数迭代方法,3.2.3为直接策略搜索方法,3.2.4给出了值函数方法和策略搜索方法的对比。
策略迭代算法包括策略评估和策略改善两个步骤。在策略评估中,给定策略,计算该策略下每个状态的值函数。然后,利用该值函数和贪婪策略得到新的策略。如此循环下去,最终得到最优策略。

从策略迭代的伪代码(图2)看到,进行策略改善之前需要得到收敛的值函数。值函数收敛往往需要很多次迭代。当我们在评估一次之后就进行策略改善,则称为值函数迭代算法。

策略搜索是将策略参数化,即 :利用参数化的线性函数或非线性函数(如神经网络)表示策略,寻找最优的
,使得强化学习的目标——累积回报的期望
最大。前面的值函数方法中,迭代计算的是值函数,在根据值函数改善策略;而在策略搜索方法中,我们直接对策略进行迭代计算,也就是迭代更新策略的参数值,直到累积回报的期望最大,此时的参数所对应的策略为最优策略。
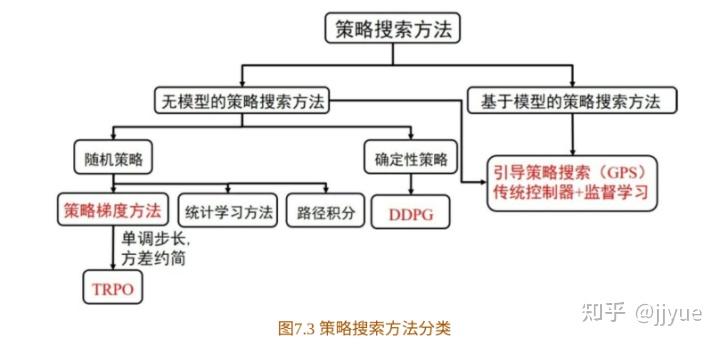
策略搜索方法按照是否利用模型,可以分为无模型的策略搜索方法和基于模型的策略搜索方法。
其中,无模型的策略搜索方法根据策略是采用随机策略还是确定性策略可以为随机策略搜索方法和确定性策略搜索方法。随机策略搜索方法是最先发展起来的是策略梯度方法;但策略梯度方法存在学习速率难以确定的问题,为回避问题,由提出了基于统计学习的方法和基于路径积分的方法。但TRPO方法没有回避该问题,二是找到了替代损失函数——利用优化方法在每个局部点找到使损失函数单调非增的最优步长。
a) 直接策略搜索?法是对策略进?参数化表?,与值函数?法中对值函数进?参数化表?相?,策略参数化更简单,有更好的收敛性。
b)利?值函数?法求解最优策略时,策略改善需要求解 , 当要解决的问题动作空间很?或者动作为连续集时,该式?法有效求解。
c)直接策略搜索?法经常采?随机策略,因为随机策略可以将探索直接集成到所学习的策略之中。
a)策略搜索的?法容易收敛到局部最?值;
b)评估单个策略时并不充分,?差较?。
上一篇: JAVA实现线性优化的单纯形算法
下一篇: 推进市场监管创新 持续优化营商环境
公司地址
广东省广州市某某工业区88号联系电话
400-123-4567电子邮箱
admin@youweb.comCopyright © 2012-2018 IM电竞真空泵水泵销售中心 版权所有 课ICP备985981178号



